Menu
Home » 3X-TMiner
3X-TMiner : 과학서적 정보 구조화 플랫폼
3천만건 이상의 과학서적을 텍스트 마이닝하여 연결된 유전자, 질병, 약물, 그리고 임상시험 정보를 제공합니다

NCBI Pubmed의 약 3천만건 논문을 NLP 기법을 적용하여 연구자가 검색한 내용에 대해서 관련된 약물, 질병, 유전자, 유전자 변이 뿐만 아니라
연구 동향을 파악할 수 있는 플랫폼을 구축하였습니다.
소개
NCBI PubMed는 전 세계적으로 가장 큰 과학 문헌 저장소로 자리잡고 있으며, 이 데이터베이스는 매년 기하급수적으로 확장되고 있습니다. 이 포괄적인 리소스의 중요성은 거대한 크기를 뛰어 넘으며, 풍부한 출판 문헌에서 얻은 상당한 통찰력을 제공할 수 있는 잠재력을 가지고 있습니다. 연구자들은 이 광범위한 데이터 세트를 탐구함에 따라 귀중한 정보를 추출하고 동향을 파악하며 광범위한 과학 분야에 걸쳐 더 깊은 이해를 얻을 수 있습니다. 이 플랫폼은 협업을 촉진하고 지식을 공유할 뿐만 아니라 과학계가 정보에 입각한 결정을 내리고 가설을 수립하며 획기적인 발견을 유도할 수 있도록 지원합니다. 연구자들은 NCBI PubMed의 방대한 저장소를 활용하여 발전을 주도하고 연구 방향을 개선하며 궁극적으로 과학적 이해의 집단 진화에 기여할 수 있는 수많은 미개척 지식을 확보할 수 있습니다.
도전
NCBI PubMed는 전 세계적으로 가장 큰 과학 문헌 저장소로 자리잡고 있으며, 이 데이터베이스는 매년 기하급수적으로 증가하고 있으며, 3천만 개가 넘는 방대한 기록 컬렉션을 보유하고 있습니다. 이 포괄적인 리소스의 중요성은 그 엄청난 크기를 뛰어 넘으며, 풍부한 출판 문헌에서 얻은 실질적인 통찰력을 제공할 수 있는 잠재력을 가지고 있습니다.
연구자들은 이 광범위한 데이터 세트를 조사하면서 귀중한 정보를 추출하고 동향을 파악하며 광범위한 과학 분야에 대해 더 깊은 이해를 할 수 있습니다. 이 플랫폼은 협력을 촉진하고 지식을 공유하는 데 도움이 될 뿐만 아니라 과학계가 정보에 입각한 결정을 내리고 가설을 수립하며 획기적인 발견을 유도할 수 있도록 지원합니다.
NCBI PubMed의 방대한 저장소를 활용함으로써 연구자들은 발전을 주도하고 연구 방향을 개선하며 궁극적으로 과학적 이해의 집단적 진화에 기여할 수 있는 수많은 미개척 지식을 확보할 수 있습니다.
핵심 기술의 활용
3BIGS는 방대한 NCBI PubMed 데이터베이스를 효율적으로 관리하고 업데이트하는 문제를 해결하기 위해 독창적으로 해결책을 고안했습니다. 그들의 해결책은 실시간 최신 정보를 연구자들에게 제공하기 위해 데이터베이스를 로컬에 저장하고 지속적인 새로 고침을 보장하는 것을 포함합니다. 로컬 저장소가 설립되면 3BIGS는 최첨단 자연어 처리(NLP) 프로그램을 통합하여 초록을 꼼꼼하게 처리합니다. 이것은 유전자, 질병, 화학 화합물 및 참조 SNP와 같은 필수 구성 요소를 추출하여 NLP의 힘을 활용하여 귀중한 통찰력을 얻는 것을 의미합니다.
데이터 무결성을 유지하기 위해 추출된 정보는 2단계 개선 과정을 거칩니다. 먼저 내부 품질 관리 메커니즘을 사용하여 잠재적인 오류와 불일치를 제거합니다. 그 후 최상의 정확성과 정확성을 보장하기 위해 부지런한 인간 큐레이션 단계를 수행합니다. 이 엄격한 접근 방식은 도출된 데이터가 최고 수준의 품질과 신뢰성을 달성할 수 있도록 보장하여 연구자에게 매우 귀중한 리소스가 됩니다. 3BIGS는 기술 혁신, NLP 숙련도 및 세심한 큐레이션을 원활하게 병합하여 연구자에게 NCBI PubMed 데이터베이스의 최신 정확하고 강력한 정보를 제공하는 포괄적인 솔루션을 개발했습니다.
구조화되어 있지 않은 정보
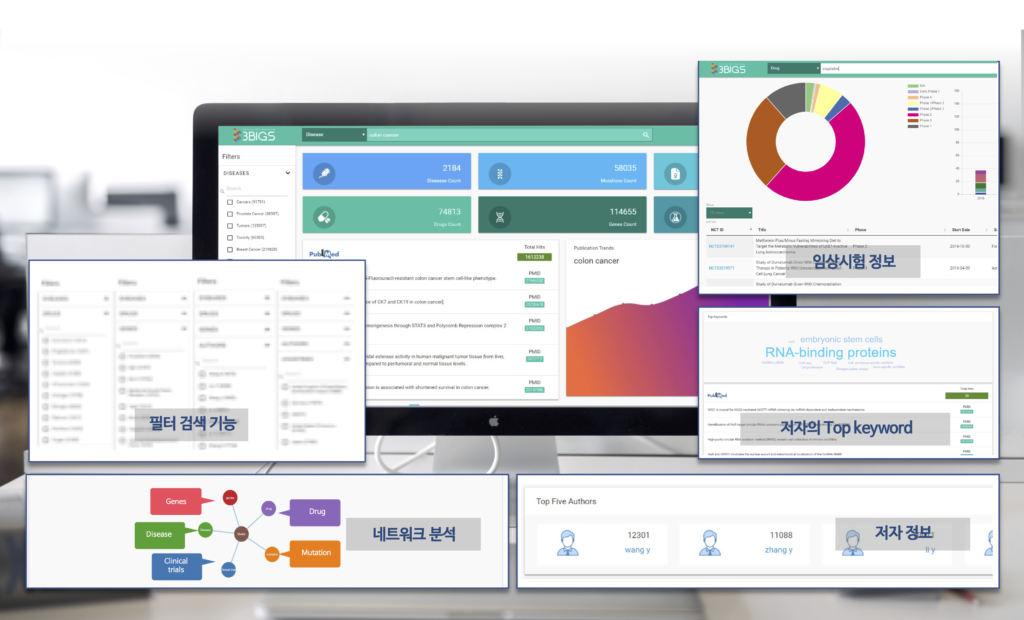
일반적인 과학논문에 대한 텍스트 마이닝이 아닌 생물정보, 임상시험, 약물정보, 투자, 논문 등 다양한 정보들을 통합 구조화하여 3X-TMiner 만의 차별성을 갖습니다.
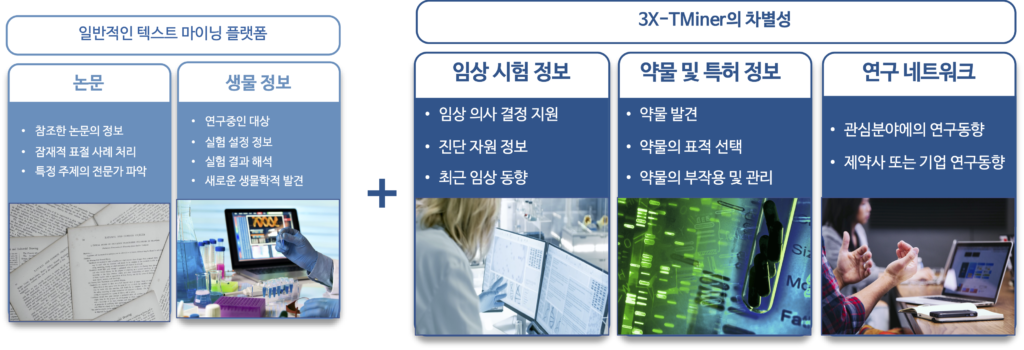
텍스트 마이닝 기술 적용
과학서적의 초록 내용을 가져와 유전자, 질병, 약물, 네트워크 등 다양한 전문용어를 NLP (Natural Language Processing)기법을 이용하여 텍스트 마이닝 합니다.


과학서적 데이터 구조화 및 활용
약 3천만건 이상의 과학서적을 기반으로 유전자, 질병, 약물, 임상정보 등 구조화하고, 연구의 흐름을 파악 할 수 있도록 다양한 정보를 지원합니다